







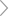




随着文字识别技术的迅速发展,其相关领域的应用在人们日常生活中得到了极大的认可。将纸质发票通过拍照转化成电子图片,再利用OCR字符识别技术识别图片中的票据信息,自动录入到系统中,可有效解决票据信息人工录入时效率低、准确率低的问题,大幅度提升工作效率。
基于Tesseract-OCR引擎的发票内容提取与实时识别:首先利用OpenCV对发票图像进行预处理滤波、自适应阈值等一系列预处理得到二值图像;然后利用形态学中的开运算提取表格全域线段,进行表格位置提取,并结合表格交点坐标与自定义模板,实现表头与内容自适应适配;最后利用jTessBoxEditor对表格区域内容进行字库训练优化,最终实现基于Tesseract-OCR的字符识别。发票的OCR识别主要包括图像预处理、表格提取、内容匹配、字符识别4个模块:

OCR总体架构
一、图像预处理。预处理即对发票原图进行简单的形态学操作,获取最佳的二值图像。
二、表格提取。对二值图像进行线段识别,以实现表格提取。表格由水平线和垂直线组成,因此需分别在两个方向上对发票进行线段提取,提取线段的形态学操作就是通过自定义的结构元素,构造对指定形状敏感的形态学运算,再通过膨胀和腐蚀操作处理敏感像素。提取水平线时创建自定义内核形态为竖向矩形,此时的敏感对象是垂直线段,通过开运算腐蚀垂直方向像素,水平线即被保留;提取垂直线段时创建自定义内核形态为横向矩形。图像所有线段均提取后,对输出结果进行“与”操作以求得交点坐标,发票内容通过坐标对进行匹配。再对提取出的水平线图、垂直线图做加法合并,即可得到完整的表格框线图。

发票原图

发票提取图
三、内容匹配。发票内容为多行多列文本,对发票先分割再识别,把含有用信息的表格单独切割,每个表格都是一张图像,对于含多行文本的表格,通过算法对其进行再分割,使得到的每张图像都只含一列文本。
四、字符识别。发票文档由中英文、数字和特殊符号共同组成,Tesseract-OCR引擎自带的字库识别准确率并不高,引入jTessBoxEditor来训练专门针对发票识别的字库。通过修正坐标,将内容与表格边框分隔开,使表头与内容精准匹配,从而实现任意区域下对特定表格进行内容提取,并高效精准识别。

图 数字训练对比

图 汉字训练对比
随着中国的科技发展愈来愈好,OCR技术应用越来越广泛,如证件识别、银行卡识别、车牌识别、表格识别、票据识别、护照识别、名片识别、人脸识别、文档识别、人证合一、营业执照识别、发票识别、VIN码识别等各种涵盖生活、工作的技术核心,目前包含银行、保险、金融、税务、海关、公安、边检、物流、电信工商管理、图书馆、户籍管理、审计等很多行业都已经应用了OCR技术。
关于Tesseract:在当前主流文字识别技术中,Tesseract作为主要被使用的开源引擎之一,是20世纪80年代中期由惠普实验室开发、谷歌公司维护的开源OCR(Optical Character Recognition,光学字符识别)引擎。在这些年Tesseract引擎更新了3.0的版本之后,其与Microsoft Office Document Imaging(MODI)相比,开始支持长短时记忆神经网络(LSTM),可以通过不断的数据集进行训练训练,将文字识别的准确率不断提高,现已经支持对一百多门语言的文字进行识别处理。